
事件循环
Node.js 事件循环一: 浅析
理解事件循环系列第一步 浅析和总览
多数的网站不需要大量计算,程序花费的时间主要集中在磁盘 I/O 和网络 I/O 上面
SSD读取很快,但和CPU处理指令的速度比起来也不在一个数量级上,而且网络上一个数据包来回的时间更慢: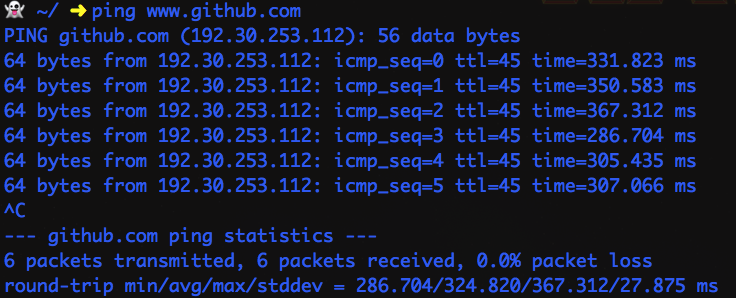
一个数据包来回的延迟平均320ms(我网速慢,ping国内网站会更快),这段时间内一个普通 cpu 执行几千万个周期应该没问题
因此异步IO就要发挥作用了,比如用多线程,如果用 Java 去读一个文件,这是一个阻塞的操作,在等待数据返回的过程中什么也干不了,因此就开一个新的线程来处理文件读取,读取操作结束后再去通知主线程。
这样虽然行得通,但是代码写起来比较麻烦。像 Node.js V8 这种无法开一个线程的怎么办?
先看下面函数执行过程
栈 Stack
当我们调用一个函数,它的地址、参数、局部变量都会压入到一个 stack 中
function fire() {
const result = sumSqrt(3, 4)
console.log(result);
}
function sumSqrt(x, y) {
const s1 = square(x)
const s2 = square(y)
const sum = s1 + s2;
return Math.sqrt(sum)
}
function square(x) {
return x * x;
}
fire()
|
|
函数 fire 首先被调用
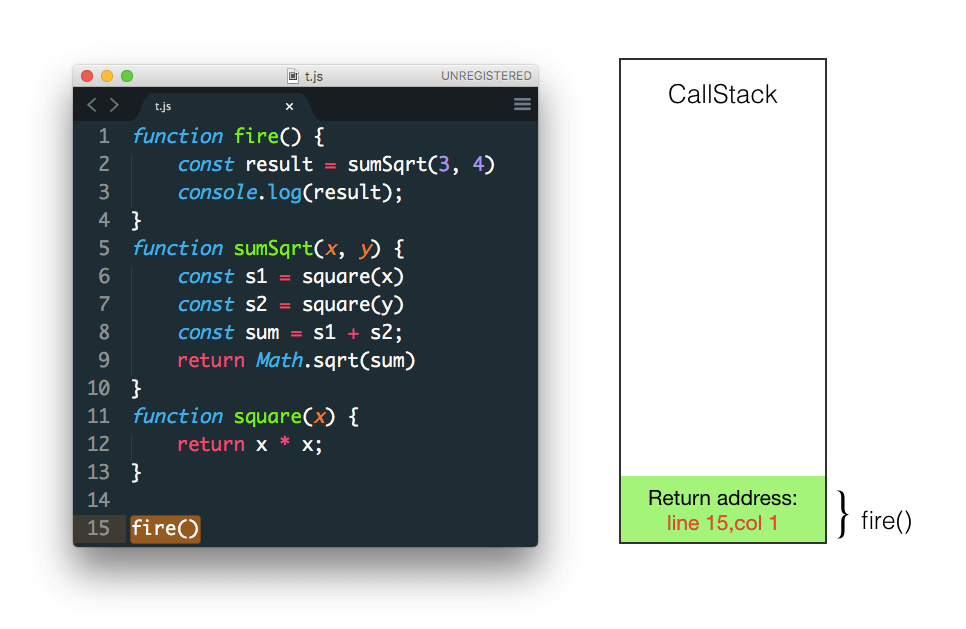
fire 调用 sumSqrt 函数 参数为3和4

之后调用 square 参数为 x, x==3

当 square 执行结束返回时,从 stack 中弹出,并将返回值赋值给 s1
s1加入到 sumSqrt 的 stack frame 中

以同样的方式调用下一个 square 函数


在下一行的表达式中计算出 s1+s2 并赋值给 sum

之后调用 Math.sqrt 参数为sum

现在就剩下 sumSqrt 函数返回计算结果了

返回值赋值给 result
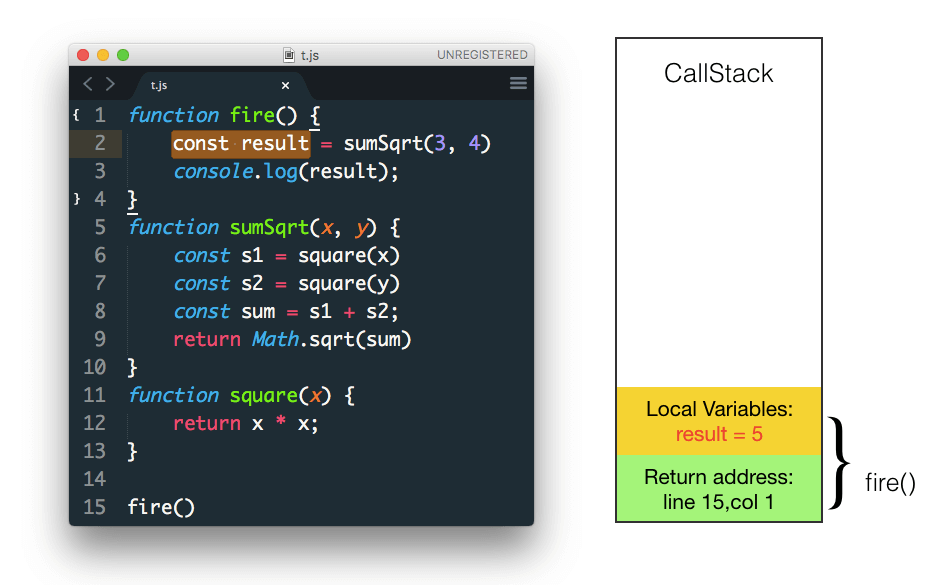
在 console 中打印出 result

最终 fire 没有任何返回值 从stack中弹出 stack也清空了
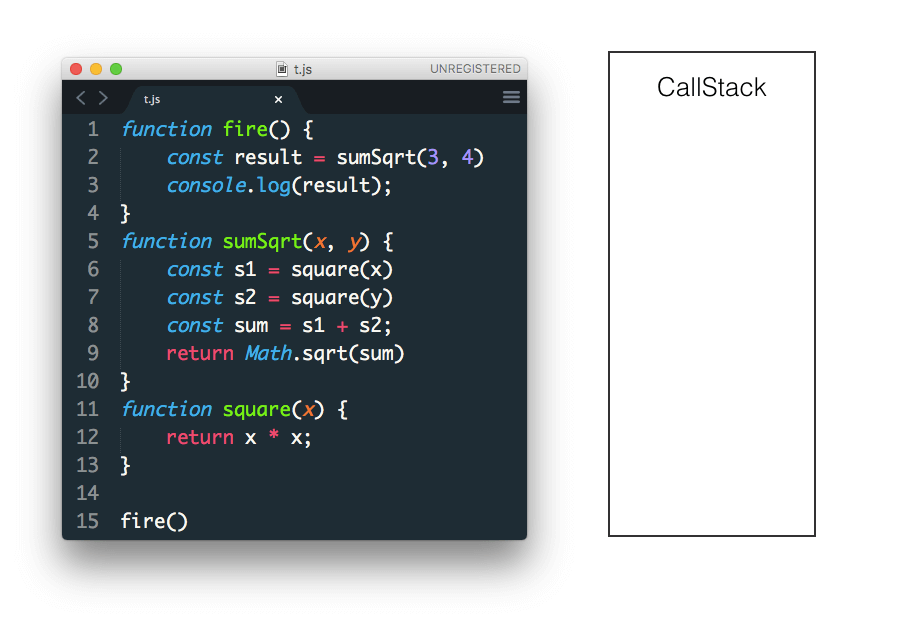
当函数执行完毕后本地变量会从 stack 中弹出,这只有在使用 numbers string boolean 这种基本数据类型时才会发生。而对象、数组的值是存在于 heap(堆) 中的,stack 只存放了他们对应的指针。
当函数之行结束从 stack 中弹出来时,只有对象的指针被弹出,而真正的值依然存在 heap 中,然后由垃圾回收器自动的清理回收。
事件循环
通过一个例子来了解函数的执行顺序
'use strict'
const express = require('express')
const superagent = require('superagent')
const app = express()
app.get('/', getArticle)
function getArticle(req, res) {
fetchArticle(req, res)
print()
}
const aids = [4564824, 4506868, 4767667, 4856099, 7456996];
function fetchArticle(req, res) {
const aid = aids[Math.floor(Math.random() * aids.length)]
superagent.get(`http://news-at.zhihu.com/api/4/news/${aid}`)
.end((err, res) => {
if(err) {
console.log('error ......');
return res.status(500).send('an error ......')
}
const article = res.body
res.send(article)
console.log('Got an article')
})
console.log('Now is fetching an article')
}
function print(){
console.log('Print something')
}
app.listen('5000')
请求 http://localhost:5000/ 后打印出
Now is fetching an article
Print something
Got an article
虽然 V8 是单线程的,但底层的 C++ API 却不是。这意味着当我们执行一些非阻塞的操作,Node会调用一些代码,与引擎里的js代码同时执行。一旦这个隐藏的线程收到了等待的返回值或者抛出一个异常,之前提供的回调函数就会执行。
上面的说的Node调用的一些代码其实就是 libuv,一个开源的跨平台的异步 I/O 。最初就是为 Node.js 开发的,现在很多项目都在用
任务队列
javascript 是单线程事件驱动的语言,那我们可以给时间添加监听器,当事件触发时,监听器就能执行回调函数。
当我们去调用 setTimeout http.get fs.readFile, Node.js 会把这些定时器、http、IO操作发送给另一个线程以保证V8继续执行我们的代码。
然而我们只有一个主线程和一个 call-stack ,这样当一个读取文件的操作还在执行时,有一个网络请求request过来,那这时他的回调就需要等stack变空才能执行。
回调函数正在等待轮到自己执行所排的队就被称为任务队列(或者事件队列、消息队列)。每当主线程完成前一个任务,回调函数就会在一个无限循环圈里被调用,因此这个圈被称为事件循环。
我们前面那个获取文章的例子的执行顺序就会如下:
- express 给 request 事件注册了一个 handler,并且当请求到达路径 ‘/‘ 时来触发handler
- 调过各个函数并且在端口 5000 上启动监听
- stack 为空,等待 request 事件触发
- 根据传入的请求,事件触发,express 调用之前提供的函数
getArticle getArticle压入(push) stackfetchArticle被调用 同时压入 stackMath.floor和Math.random被调用压入 stack 然后再 弹出(pop), 从 aids 里面取出的一个值被赋值给变量 aidsuperagent.get被执行,参数为'http://news-at.zhihu.com/api/4/news/${aid}',并且回调函数注册给了end事件- 到
http://news-at.zhihu.com/api/4/news/${aid}的HTTP请求被发送到后台线程,然后函数继续往下执行 'Now is fetching an article'打印在console中。 函数fetchArticle返回print函数被调用,'Print something'打印在console中- 函数
getArticle返回,并从 stack 中弹出, stack 为空 - 等待
http://news-at.zhihu.com/api/4/news/${aid}发送相应信息 - 响应信息到达,
end事件被触发 - 注册给
end事件的匿名回调函数被执行,这个匿名函数和他闭包中的所有变量压入stack,这意味着这个匿名函数可以访问并修改express,superagent,app,aids,req,res,aid的值以及之前所有已经定义的函数 - 函数
res.send()伴随着 200 或 500 的状态码被执行,但同时又被放入到后台线程中,因此 响应流 不会阻塞我们函数的执行。匿名函数也被 pop 出 stack。
Microtasks Macrotasks
任务队列不止一个,还有 microtasks 和 macrotasks
microtasks:
- process.nextTick
- promise
- Object.observe
macrotasks:
- setTimeout
- setInterval
- setImmediate
I/O
这两个的详细区别下一篇再写,先看一段代码console.log(‘start’)
const interval = setInterval(() => {
console.log('setInterval')}, 0)
setTimeout(() => {
console.log('setTimeout 1') Promise.resolve() .then(() => { console.log('promise 3') }) .then(() => { console.log('promise 4') }) .then(() => { setTimeout(() => { console.log('setTimeout 2') Promise.resolve() .then(() => { console.log('promise 5') }) .then(() => { console.log('promise 6') }) .then(() => { clearInterval(interval) }) }, 0) })}, 0)
Promise.resolve()
.then(() => { console.log('promise 1') }) .then(() => { console.log('promise 2') })
理解了node的事件循环还是比较容易得出答案的:
start
promise 1
promise 2
setInterval
setTimeout 1
promise 3
promise 4
setInterval
setTimeout
promise 5
promise 6
根据 WHATVG 的说明,在一个事件循环的周期(cycle)中一个 (macro)task 应该从 macrotask 队列开始执行。当这个 macrotask 结束后,所有的 microtasks 将在同一个 cycle 中执行。在 microtasks 执行时还可以加入更多的 microtask,然后一个一个的执行,直到 microtask 队列清空。
规范理解起来有点晦涩,来看下上面的例子
Cycle 1
1) setInterval 被列为 task
2) setTimeout 1 被列为 task
3) Promise.resolve 1 中两个 then 被列为 microtask
4) stack 清空 microtasks 执行
任务队列: setInterval setTimeout 1
Cycle 2
5) microtasks 队列清空 setInteval 的回调可以执行。另一个 setInterval 被列为 task , 位于 setTimeout 1 后面
任务队列: setTimeout 1 setInterval
Cycle 3
6) microtask 队列清空,setTimeout 1 的回调可以执行,promise 3 和 `promise 4 被列为microtasks`
7) promise 3 和 promise 4 执行。 setTimeout 2 被列为 task
任务队列 setInterval setTimeout 2
Cycle 4
8) microtask 队列清空 setInteval 的回调可以执行。然后另一个 setInterval 被列为 task ,位于 setTimeout 2 后面
任务队列: setTimeout 2 setInterval
9) setTimeout 2的回调执行,promise 5 和 promise 6 被列为 microtasks
现在 promise 5 和promise 6 的回调应该执行,并且 clear 掉 interval。 但有的时候不知道为什么 setInterval 还会在执行一遍,变成下面结果
...
setTimeout 2
setInterval
promise 5
promise 6
但是把上面的代码放入 chrome console 中执行却没有问题。这一点还要再根据不同的 node版本 查一下。